DOOM Eternal - Graphics Study
Doom Eternal is the successor of Doom 2016. It’s developed using the 7th iteration of id Tech, id Software’s in-house game engine. Doom 2016 has inspired me greatly on a technologic level due to its simplicity and elegance while still having a high visual quality. For Doom Eternal, this is no different. Doom Eternal has improved in many areas of which a few are worth investigating which I will try to cover in this frame breakdown.

Using the DirectXShaderCompiler C++ API
The old fxc.exe compiles to DXBC and only supports up to Shader Model 5.1. Microsoft has since introduced their new llvm-based compiler DirectXShaderCompiler (DXC) which compiles to DXIL (whereas FXC compiles to DXBC). It’s completely open-source on GitHub. It both provides command line tools and a C++ API for compiling, validating and using shaders with SM 6.0 and up.

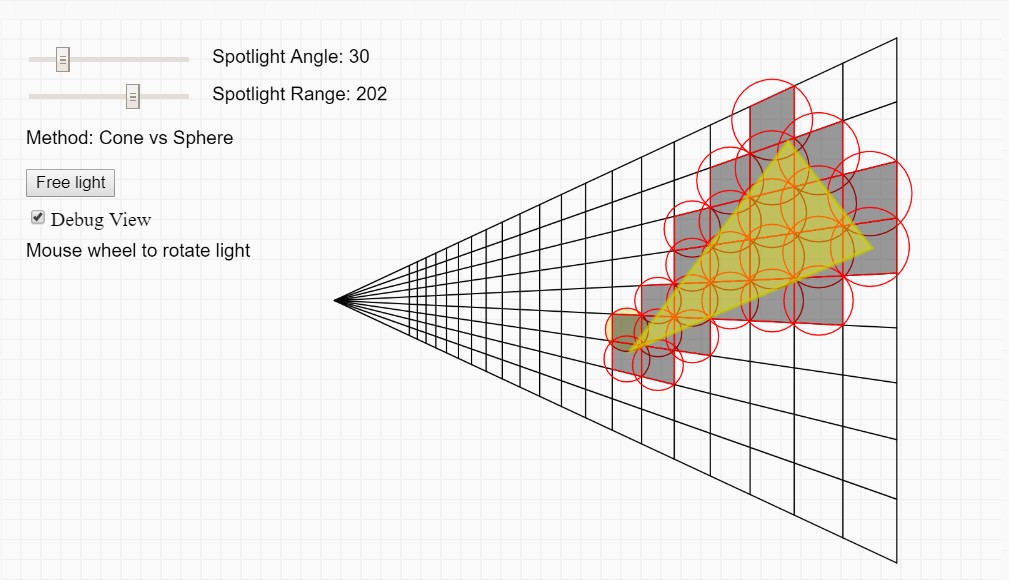
Optimizing spotlight intersection in tiled/clustered light culling
I’ve been implementing both tiled and clustered light culling with forward rendering recently and one of the things I never was quite happy with is the way spot lights were tested against the frustum voxel/AABBs. I wanted to write up something about my entire culling implementation but then I got a bit sidetracked by looking into way to improve cone culling specifically and I thought the spot light testing is an interesting case on its own.
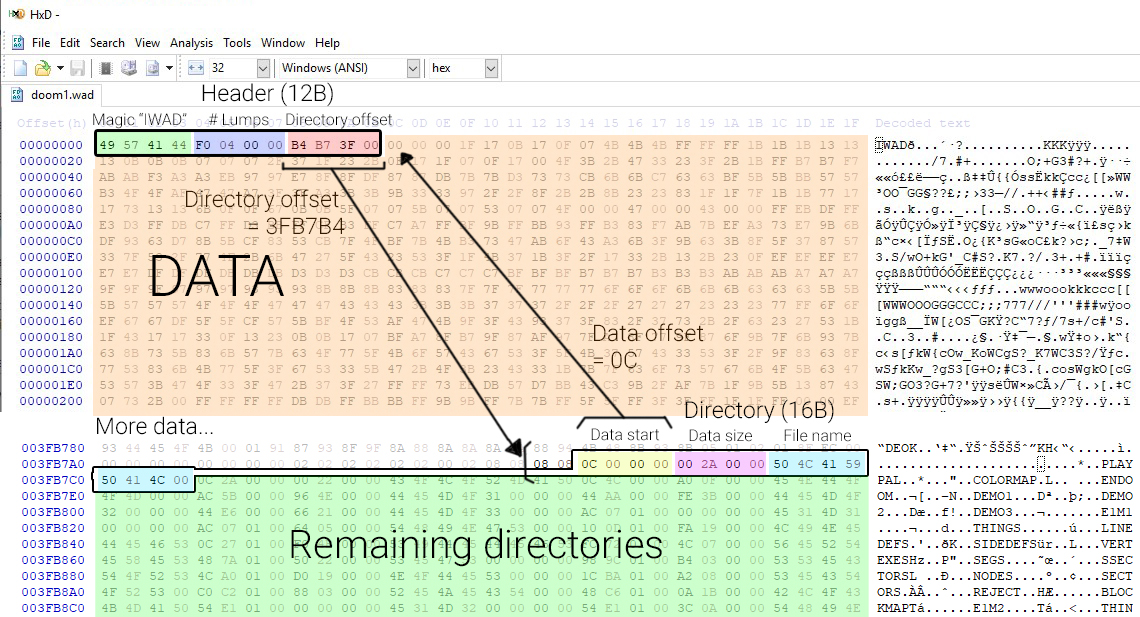
Pak files - Virtual file system
Packaging assets in large binary blobs in games is quite common. In 1992, Wolfenstein 3D introduced so called “WAD” files (Stands for “Where’s All the Data?”). This file format has been used after on Doom and eventually pretty much all games currently today in some form. It gives more flexibility to users (and developers) to create patches, mods, it provides opportunities for security measures but more importantly, it improves performance significantly as having only a few large binary files to read from is much faster than reading many small files.
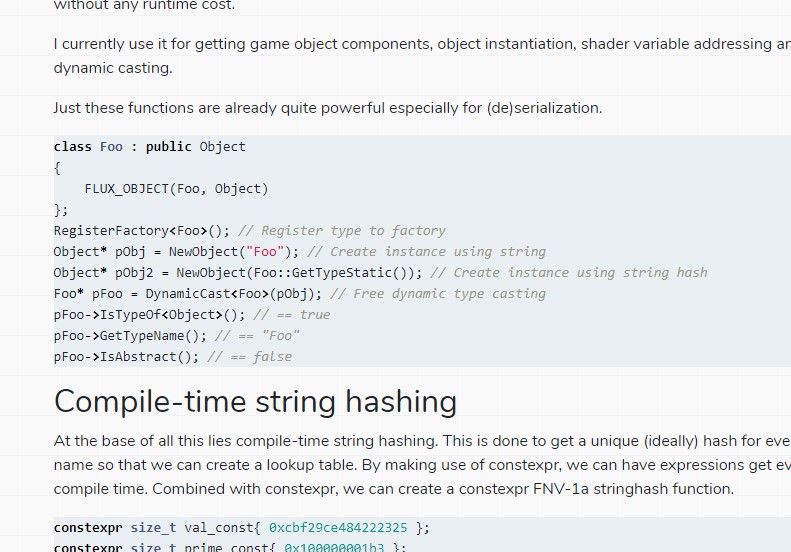
Basic compile-time type information using constexpr
When working on my game engine project, I always get distracted by new interesting things or thoughts I want to look into and one of them was reflection. Almost all commercial game engine have some kind of reflection that makes GUI editors and visual scripting possible. Unlike those engines, I didn’t look into full all-the-way reflection because I didn’t want to bloat my code with that and maintain it. I was mostly interested in very simple type reflection so before you start frowning when looking at the code, this is not meant to be a complete reflection system at all! This is quite basic but I found it to be an interesting use of compile-time expressions.
All the code can be found on GitHub.
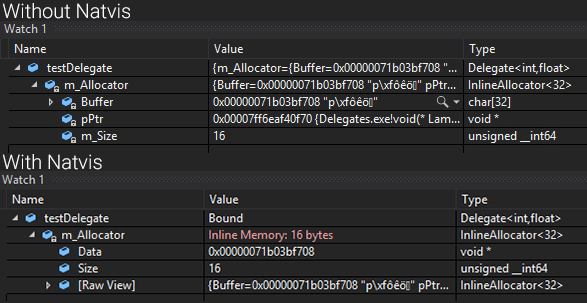
Natvis in Visual Studio
When working on the C++ delegates (see previous post), I found out about a thing called “natvis” and I never actually heard of it before even though it’s always been right under my nose when debugging Unreal Engine projects. It’s a really awesome and powerful debugging tool that allows you to define how classes should be visualized in the Visual Studio “Watch” windows and hover windows.